While developing Energy Logserver, we wonder what the nature of the work of a SOC office analyst is ? How does it happen that an expert quickly notices differences in the analyzed events? We came to the conclusion that its effectiveness is due to cyclically performed tasks. By analyzing events, he recognizes those that are typical of the infrastructure and those that are a complete surprise. The analyst performs a quick statistical assessment of the read logs, detects rare words and analyzes them in the context of the entire message. This is a very valid approach, but limited to what the operator can see on the screen.
In the Empowered AI module, we recreated the thought process of a SOC analyst. Using Artificial Intelligence, we have built an analytical rule that performs the same assessment as a human – but more precisely and faster. The “Anomaly Detection – Text” rule analyzes each log in the context of the individual words that compose it. Mathematical functions in Energy Logserver calculate the probability of occurrence of each individual word in the analyzed set. The algorithm builds a dictionary that determines the probability of a word appearing in the set. Words that we encounter often do not interest us. We focus our work on rare words. The algorithm defines then and gives them points – the rarer the word, the higher the score. Additionally, we will count the occurrence of rare words in the entire log.
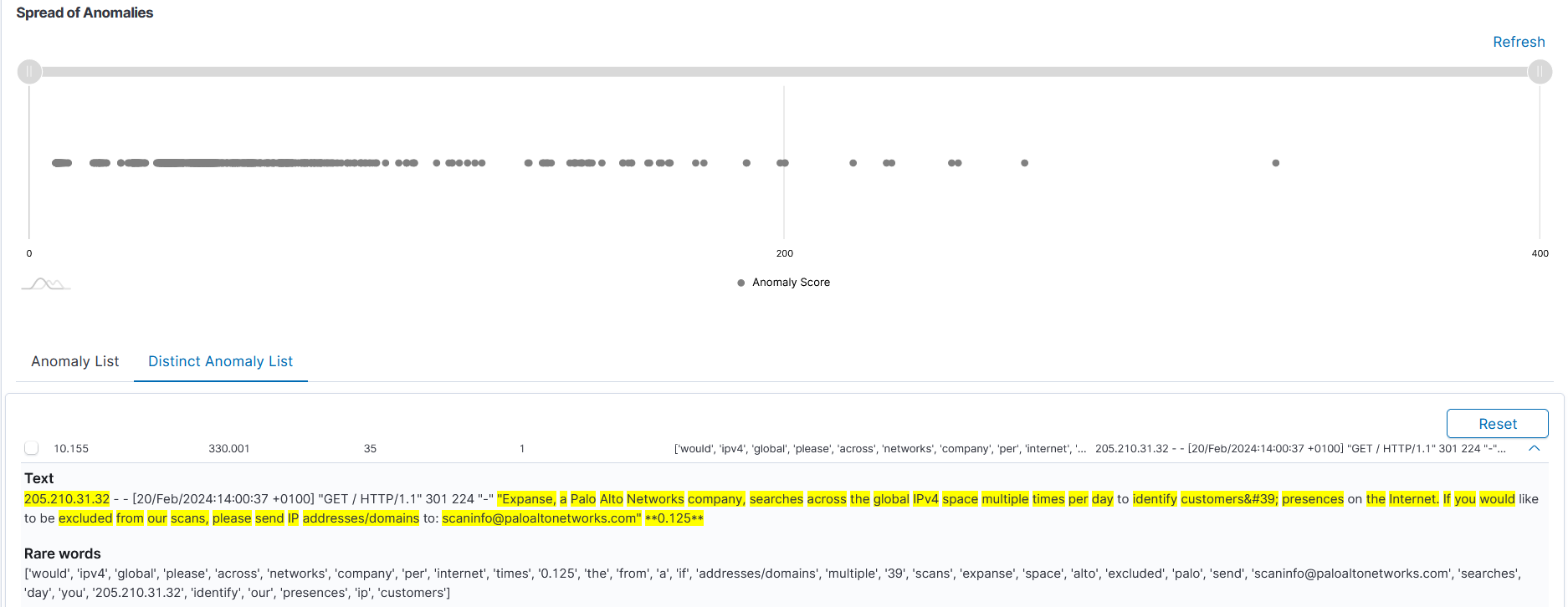
Let’s see an example of one caught entry:
Text
205.210.31.32 – – [20/Feb/2024:14:00:37 +0100] “GET / HTTP/1.1” 301 224 “-” “Expanse, a Palo Alto Networks company, searches across the global IPv4 space multiple times per day to identify customers' presences on the Internet. If you would like to be excluded from our scans, please send IP addresses/domains to: scaninfo@paloaltonetworks.com” **0.125**
Rare words
[‘would’, ‘ipv4’, ‘global’, ‘please’, ‘across’, ‘networks’, ‘company’, ‘per’, ‘internet’, ‘times’, ‘0.125’, ‘the’, ‘ from’, ‘a’, ‘if’, ‘addresses/domains’, ‘multiple’, ’39’, ‘scans’, ‘expanse’, ‘space’, ‘alto’, ‘excluded’, ‘palo’, ‘ send’, ‘scaninfo@paloaltonetworks.com’, ‘searches’, ‘day’, ‘you’, ‘205.210.31.32’, ‘identify’, ‘our’, ‘presences’, ‘ip’, ‘customers’]
These detections make up the following calculations:
Rare words: 35
Single word anomaly points: 10,155
Entire logo anomaly points: 330,001
Number of occurrences of the indicated logo as a whole: 1
This time the entry turned out to be harmless. Palo does market research.
From the moment we gave the words and logos anomaly points, we can compare them.
In the image we can see how the log anomaly points are distributed on the axis.
What comes next in Energy Logserver? I will mention it in one breath: Empowered AI rule schedule, alerting based on anomaly score, real time anomaly score, saving models and building a model library for various sources, user community for saved models… And these are just the features that are already waiting for publication.