
Events from information systems are of a repetitive nature. Within the sources of the same type we can expect a unified form of messages. Incidents and application errors are similar to each other and only a trained eye of an analyst allows to focus on a specific problem. The unique knowledge of the analytical team concerns the knowledge of the organization and its processes, data sources, sensitive processing time periods, specific users working in the system and many other attributes related to the indicated log entry. A person gives the meaning to data on the basis of their own classification of the problem and automatically estimates the risk associated with the event.
This issue is addressed with Risk Management module in Energy Logserver. The platform operator has the ability to influence the level of significance for the observed event by the appropriate recognition of the characteristics of the source system like: user account, process name or other attribute.
In practice, for any data field, e.g. hostname, we create a new risk category, e.g. Production.
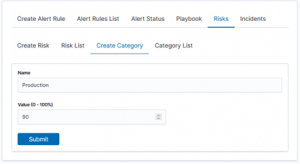
Each category has own points. The value 50 is the starting state. We attach objects to the indicated category based on the data from the index.
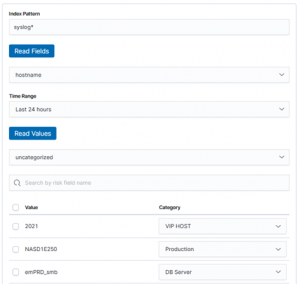
Create Alert Rule tab allows you to select values based on indexed data. From that moment, we have our Data Objects assigned to the risk categories. Highest time to use. When building the Alert, we provide the “Risk Key” field for which the risk analysis will be conducted.
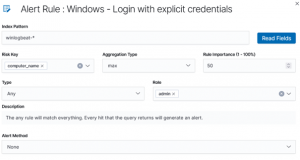
Our rule also has a significance level, starting from the value of 50. Thanks to this, the final risk index will be calculated on the basis of the value of the analyzed objects and the significance of the rule itself. Final method that the risk points are calculated are coming from the settings of “Aggregation type”.
From now on, in the moment of an incident detection for our rule, the system will automatically calculate the “Risk Key” value and register it as an event attribute.
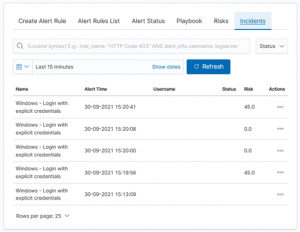
It is easy to see that this mechanism is generic and can be used to identify any categories and their risks. Typical use case is to create a high-risk groups for:
- users / logins of the management staff,
- production systems,
- critical software and applications,
- DMZ IP address zones,
- specific communication ports.